Run in Postman
- Conditions des fichiers
- Les propriétés requises pour les imports de fiches d’informations et d’activités
- Les propriétés requises pour les importations de participants à des événements marketing
Démarrer un import
Vous pouvez commencer un import en effectuant une requêtePOST à /crm/v3/imports avec un corps de requête qui spécifie comment mapper les colonnes de votre fichier d’import aux propriétés associées dans HubSpot.
Les imports d’API sont envoyés sous forme de requêtes de données de formulaire, le corps de la requête contenant les champs suivants :
- importRequest : un champ de texte qui contient le JSON de requête.
- files : un champ de fichier qui contient le fichier d’import.
Content-Type avec une valeur multipart/form-data.
La capture d’écran ci-dessous illustre ce à quoi pourrait ressembler votre requête lorsque vous utilisez une application telle que Postman :
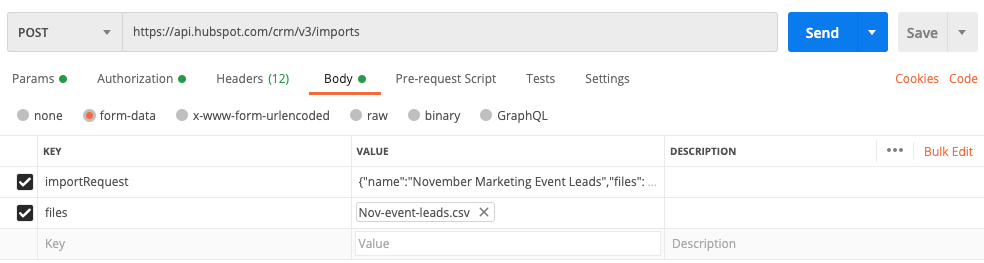
Formater les données importRequest
Dans votre requête, définissez les détails du fichier d’import, y compris le mappage des colonnes de la feuille de calcul avec les données HubSpot. Votre requête doit inclure les champs suivants :- name : nom de l’import. Dans HubSpot, il s’agit du nom affiché dans l’outil d’import ainsi que du nom que vous pouvez mentionner dans d’autres outils, tels que des listes.
- importOperations : un champ facultatif utilisé pour indiquer si l’import doit créer et mettre à jour, uniquement créer ou uniquement mettre à jour des fiches d’informations pour un objet ou une activité donné. Incluez l’élément
objectTypeIdpour l’objet/l’activité et si vous souhaitezUPSERT(créer et mettre à jour),CREATEouUPDATEdes fiches d’informations. Par exemple, le champ ressemblerait à ceci dans votre requête :"importOperations": {"0-1": "CREATE"}. Si vous n’incluez pas ce champ, la valeur par défaut utilisée pour l’import seraUPSERT. - dateFormat : le format des dates incluses dans le fichier. Par défaut, cette valeur est définie sur
MONTH_DAY_YEAR, mais vous pouvez également utiliserDAY_MONTH_YEARouYEAR_MONTH_DAY. - marketableContactImport : un champ facultatif pour indiquer le statut marketing des contacts dans votre fichier d’import. Ceci est utilisé uniquement lors de l’import de contacts dans des comptes qui ont accès aux contacts marketing. Pour définir les contacts dans le fichier comme marketing, utilisez la valeur
true. Pour définir les contacts dans le fichier comme non marketing, utilisez la valeurfalse. - createContactListFromImport : un champ facultatif pour créer une liste statique de contacts à partir de votre import. Pour créer une liste à partir de votre fichier, utilisez la valeur
true. - files : un tableau qui contient des informations sur votre fichier d’import.
- fileName : le nom du fichier d’import.
- fileFormat : le format du fichier d’import. Pour les fichiers CSV, utilisez la valeur
CSV. Pour les fichiers Excel, utilisez la valeurSPREADSHEET. - fileImportPage : contient le tableau
columnMappingsrequis pour mapper les données de votre fichier d’import aux données HubSpot. Découvrez-en davantage sur le mappage des colonnes ci-dessous.
Mapper des colonnes de fichiers à des propriétés HubSpot
Dans le tableaucolumnMappings, incluez une entrée pour chaque colonne de votre fichier d’import, en respectant l’ordre des en-têtes de colonnes de votre feuille de calcul.
Pour chaque colonne, ajoutez les champs suivants :
- columnObjectTypeId : le nom ou la valeur
objectTypeIdde l’objet ou de l’activité auquel/à laquelle les données appartiennent. Consultez cet article pour une liste complète des valeursobjectTypeId. - columnName : le nom de l’en-tête de colonne. Il doit correspondre exactement au nom de l’en-tête de colonne dans le fichier.
- propertyName : le nom interne de la HubSpot vers laquelle les données seront mappées. Pour la colonne commune dans les imports multi-fichiers,
propertyNamedoit êtrenulllorsque le champtoColumnObjectTypeIdest utilisé. - columnType : utilisé pour spécifier qu’une colonne contient une propriété d’identifiant unique. En fonction de la propriété et de l’objectif de l’import, utilisez l’une des valeurs suivantes :
- HUBSPOT_OBJECT_ID : l’identifiant d’une fiche d’informations. Par exemple, votre fichier d’import de contacts peut contenir un ID de fiche d’informations qui stocke l’ID de l’entreprise à laquelle vous souhaitez associer les contacts.
- HUBSPOT_ALTERNATE_ID : un identifiant unique autre que l’ID de fiche d’informations. Par exemple, votre fichier d’import de contacts peut contenir une colonne Adresse e-mail qui stocke les adresses e-mail des contacts.
- FLEXIBLE_ASSOCIATION_LABEL : incluez ce type de colonne pour indiquer que la colonne contient des libellés d’associations.
- ASSOCIATION_KEYS : pour les imports d’associations d’objets identiques uniquement, incluez ce type de colonne pour l’identifiant unique des mêmes fiches d’informations d’objets que vous associez. Par exemple, dans votre requête d’import d’associations de contacts, la colonne [ID de fiche d’informations/adresse e-mail] du contact associé doit avoir un élément
columnTypedeASSOCIATION_KEYS. Découvrez-en davantage sur la configuration de votre fichier d’import pour l’import d’associations d’objets identiques.
- toColumnObjectTypeId : pour les imports de plusieurs fichiers ou objets, le nom ou
objectTypeIdde l’objet auquel appartient la propriété de colonne commune ou le libellé d’association. Incluez ce champ pour la propriété de colonne commune dans le fichier de l’objet auquel la propriété n’appartient pas. Par exemple, si vous associez des contacts et des entreprises dans deux fichiers avec la propriété de contact Adresse e-mail comme colonne commune, inclueztoColumnObjectTypeIdpour la colonne Adresse e-mail dans le fichier de l’entreprise. - foreignKeyType : pour les imports multi-fichiers uniquement, le type d’association que la colonne commune doit utiliser, spécifié par
associationTypeIdetassociationCategory. Incluez ce champ pour la propriété de colonne commune dans le fichier de l’objet auquel la propriété n’appartient pas. Par exemple, si vous associez des contacts et des entreprises dans deux fichiers avec la propriété de contact Adresse e-mail comme colonne commune, incluezforeignKeyTypepour la colonne Adresse e-mail dans le fichier de l’entreprise. - associationIdentifierColumn : pour les imports multi-fichiers uniquement, indique la propriété utilisée dans la colonne commune pour associer les fiches d’informations. Incluez ce champ pour la propriété de colonne commune dans le fichier de l’objet auquel la propriété appartient. Par exemple, si vous associez des contacts et des entreprises dans deux fichiers avec la propriété de contact Adresse e-mail comme colonne commune, définissez
associationIdentifierColumnsurtruepour la colonne E-mail dans le fichier de contact.
Importer un fichier avec un objet
Voici un exemple de corps de requête pour l’import d’un fichier pour créer des contacts :- JSON
Importer un fichier avec plusieurs objets
Vous trouverez ci-dessous un exemple de corps de requête d’import et d’association de contacts et d’entreprises dans un fichier avec des libellés d’associations :- JSON
Importer plusieurs fichiers
Vous trouverez ci-dessous un exemple de corps de requête d’import et d’association de contacts et d’entreprises dans deux fichiers, où la propriété de contact Adresse e-mail est la colonne commune dans les fichiers :- JSON
importId que vous pourrez utiliser pour récupérer ou annuler l’import. Une fois terminé, vous pouvez afficher l’import dans HubSpot, mais les imports effectuées via l’API ne seront pas disponibles en tant qu’option lors du filtrage des fiches d’informations selon l’import dans les vues, les listes, les rapports ou les workflows.
Obtenir des imports précédents
Pour récupérer tous les imports depuis votre compte HubSpot, effectuez une requêteGET à /crm/v3/imports/. Pour récupérer des informations pour un import spécifique, effectuez une requête GET à /crm/v3/imports/{importId}.
Lorsque vous récupérez des imports, des informations sont renvoyées, y compris le nom de l’import, la source, le format de fichier, la langue, le format de date et les mappages de colonnes. L’élément state de l’import sera également renvoyé et peut être l’un des éléments suivants :
STARTED: HubSpot reconnaît que l’import existe, mais son traitement n’a pas encore commencé.PROCESSING: L’import est en cours de traitement.DONE: L’import est terminé. Tous les objets, activités ou associations ont été mis à jour ou créés.FAILED: Une erreur n’a pas été détectée lors du démarrage de l’import. L’import n’a pas été terminé.CANCELED: L’utilisateur a annulé l’export alors qu’il se trouvait dans l’un des étatsSTARTED,PROCESSINGouDEFERRED.DEFERRED: Le nombre maximal d’imports simultanés (trois) est atteint. L’import commencera une fois que le traitement de l’un des autres sera terminé.
Annuler l’import
Pour annuler un import actif, effectuez une requêtePOST à /crm/v3/imports/{importId}/cancel.
Afficher et résoudre les erreurs d’import
Pour afficher les erreurs pour un import spécifique, faites une requêteGET à /crm/v3/imports/{importId}/errors. Découvrez comment résoudre les erreurs d’import les plus courantes.
Pour les erreurs telles que Nombre de colonnes incorrect, Impossible d’analyser le JSON ou Le texte/HTML 404 n’est pas accepté :
- Vérifiez qu’il existe un en-tête de colonne pour chaque colonne de votre fichier et que le corps de la requête contient une entrée
columnMappingpour chaque colonne. Les critères suivants doivent être remplis :- L’ordre des colonnes dans le corps de la requête et le fichier d’import doit correspondre. Si l’ordre des colonnes ne correspond pas, le système tentera de réorganiser automatiquement mais échouera, ce qui entraînera une erreur au démarrage de l’import.
- Chaque colonne doit être mappée. Si aucune colonne n’est mappée, la requête d’import peut quand même aboutir, mais entraînera l’erreur Nombre de colonnes incorrect au démarrage de l’import.
- Assurez-vous que le nom du fichier et le champ
fileNamede votre JSON de requête correspondent et que vous avez inclus l’extension de fichier dans le champfileName. Par exemple : import_name.csv. - Vérifiez que votre en-tête comprend
Content-Typeavec une valeurmultipart/form-data.